AIトレーニングデータセットのグローバル市場規模は2024年に28億2,000万ドル、2030年までにCAGR 27.7%で拡大する見通し

市場概要
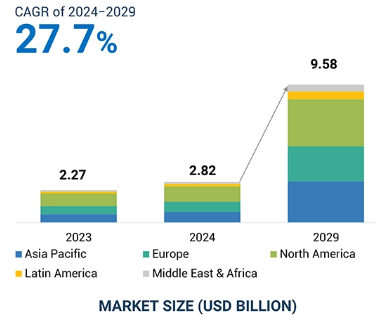
AIトレーニングデータセット市場規模は2024年に28億2000万米ドルと推定され、予測期間中に年平均成長率27.7%で成長し、2029年には95億8000万米ドルに達する見込みです。AIトレーニングデータセット市場の主要な推進力は、合成的に生成されたデータセットの採用です。例えばヘルスケアでは、合成データは実際の医療シナリオに酷似しながらもGDPRやHIPAAなどのプライバシー法に抵触しない医療画像を作成するために活用されています。このようなデータセットにより、企業は患者の個人情報を一切明かすことなく、専門的な診断や治療の提案に向けたAIモデルを作成する新たな機会が生まれました。同様の傾向は自律走行分野でも見られ、合成データセットは、実生活では観察することが危険な極端な運転状況や危険な運転状況をシミュレートしていますが、AIシステムを総合的に訓練するためには不可欠です。合成データセットを採用することで、データセットへのアクセスが容易になると同時に、手作業によるデータ収集とラベル付けにかかるコストと時間を削減することができます。コンテンツ推薦やパーソナルアシスタントなどの高度なAIアプリケーションをサポートするために、偏りのない多様なマルチモーダルデータセットが求められていることも、市場を牽引する要因です。
AI学習用データセットとは、AIシステムにパターンを認識させ、意思決定を行い、時間の経過とともに改善させるための学習に使用される膨大な量のデータのことです。AIトレーニングデータセット市場には、データセット作成とデータセット販売の両方が含まれます。データセット作成には、AIモデル学習用の高品質データセットを作成するための収集、ラベリング、合成生成、拡張が含まれます。データセット販売には、すぐに使用できるOff-the-Shelf(OTS)データセットと、カスタマイズされたデータを取引または取得するためのデータセット・マーケットプレイスが含まれます。
AIトレーニングデータセット市場の顕著な促進要因は、データセット構築に画像、テキスト、ビデオ、音声が含まれるマルチモーダルAIトレーニングデータセットの利用が増加していることです。マルチモーダルデータは、複数の種類のメディアを同時に使用する必要がある斬新なAIのユースケースに多く導入されています。例えば、アマゾンのアレクサやグーグルのアシスタントは、音声認識のための聴覚データ、コマンドを理解するためのテキストデータ、スマートフォンのカメラからの視覚画像を使用しています。同様に、ヘルスケアでは、X線、CT、MRI画像に、患者に関する構造化された情報や医師と患者の対話音声を組み合わせたマルチモーダルデータセットを使用します。これにより、AIツールは、より文脈に関連した正確な診断を推奨することができます。このことは、複数の情報を一度に処理できるAIモデルを開発する必要性を強調しています。AIのユースケースの複雑化により、マルチモーダルデータセットの統合に向けたこの人気の傾向は、特に小売、メディア&エンターテイメント、スマートホームオートメーションなど、他の業界全体で牽引されつつあります。
AIトレーニングデータセット市場における主な阻害要因は、GDPR、CCPA、最近施行されたEU AI Actなどのコンプライアンス要件が複雑化していることです。このような規制は、特に個人を特定できる情報(PII)を扱う業界において、データ収集、非識別化プロセス、AIトレーニング段階でのデータ使用方法に関する手順に厳しい制限を課しています。例えば、AIモデル用の医療データは、プライバシー規制を満たすために非常に高度にマスクされなければならず、これは自動的にデータの価値を下げ、モデルの能力に影響を与えます。2024年8月から、EUのAI法では、リスクの高いAIシステムに焦点を当てたデータの精査が、他にも何重にも追加されました。これにより、企業が規制要件に抵触することなく多様なデータセットにアクセスし、活用することはさらに難しくなると考えられます。さらに、データの偏りに関する懸念は、データセットの多様性を維持し、同時に非常に厳しいプライバシー規制を遵守することは非常に高価で複雑であるため、問題をさらに悪化させます。これらの問題はすべて一体となって、特に規制の厳しい業界の場合、AIトレーニングデータセット市場の発展のボトルネックとなっています。
AIトレーニングデータセット市場における最大のビジネスチャンスの1つは、ニッチなユースケース向けの微調整されたデータセットの開発です。農業、製薬、金融など、より焦点を絞った分野でのAI導入の増加に伴い、特殊なデータセットに対する需要が大幅に増加しています。こうした独自のデータセットを作成・販売できる企業は、汎用データセットが不足しているため、こうしたデータセットを必要とする未開拓の広大な市場を活用することができます。例えば、精密農業は衛星画像、土壌、気象情報を統合したAIデータセットに依存し、高収量を実現します。一方、創薬は生化学データを利用して分子間相互作用をモデリングし、新しい治療法を効果的に開発します。同じように、金融サービスでは、不正行為の検出を目的としたAIベースのシステムが、顧客の取引行動をリアルタイムで反映する大量のデータを使用しています。分野に特化したAIが重視され続ける中、データセット・プロバイダーには、こうした新しい市場セグメントで戦略的優位性を獲得する大きなチャンスがあります。
AIトレーニング・データセット市場における大きな課題は、データの品質、公平性、焦点、偏りに関連する潜在的なリスクです。データセットの偏りやドリフトは、意図された結果よりも歪んだ結果や偽の結果につながる可能性があります。アマゾンの採用AIツールは、女性応募者に不利な結果をもたらすことが判明しましたが、これもそのような事例のひとつです。この採用アルゴリズムは、過去10年にわたる男性の履歴書のみで構成されたデータセットで訓練されていました。そのため、採用の際にはAIシステムによって男性候補者が優先され、「女性/女性」という単語を含む履歴書はシステムによって劣っているとタグ付けされました。このようなケースは、偏った学習データが既存の不平等を永続化させ、企業の評判に損害を与える可能性があるという、問題のさらなる側面も示しています。AIシステムにおけるバイアスは他の分野でも報告されており、例えば顔認識システムでは、肌の色の濃い人が不釣り合いに誤認され、法律上の不条理につながりました。このような事例は、AIの訓練に使用されるデータセットに多様性と代表性が不可欠であること、また厳格なデータ監査レベルが必要であることを強調しています。
AI学習用データセットのエコシステムには、AWSやMicrosoftのようなデータ収集プラットフォーム、AppenやSnorkelのようなラベリングサービス、GoogleやGretelのような合成データプロバイダーが含まれます。既製のデータセットはNexdataのような企業が提供し、IBMやKotwelは完全なデータセットサービスを提供しています。Roboflowのようなデータ増強ツールはデータセットをさらに強化し、AIモデルのトレーニングライフサイクル全体をサポートします。
既製(OTS)データセットは、すぐに入手可能で取得コストが比較的安価なため、AIトレーニングデータセット市場のデータ販売セグメントをリードすると予想されます。OTSデータセットは、特定のAI目的に合わせてあらかじめ注釈が付けられているため、企業は生データの取得、処理、クリーニング、注釈付けにかかる労力とコストを大幅に削減できます。ヘルスケア、銀行、小売業、製造業など幅広い分野で人工知能の利用が加速するにつれ、分野に特化した高品質のデータセットに対する需要が高まっています。OTSのデータセットは、すぐに導入できる多様な業界関連データを提供することで、この需要に応え、モデル開発を加速し、データ品質問題のリスクを低減します。特に、大規模なデータリポジトリを持たない中小企業や新興企業にとっては、初期コストを抑えながら幅広いユースケースに対応できるOTSデータセットは、短期間でAIモデルを開発したいあらゆる組織にとって最適なモデルであり、AIトレーニングデータセット市場におけるOTSデータセットの存在感を高めています。
生成AIに特化したデータセットは、大規模言語モデル(LLM)の微調整における重要性により、AIトレーニングデータセット市場で最も速い成長率を記録する見込みです。特殊なデータセットを使用することで、LLMを微調整し、法的文書の分類、顧客支援、タスクに特化したチャットボットなど、より具体的なタスクの基礎的な理解能力を向上させることができます。そのため、企業は、ゼロから新しいLLMを構築するコストを負担することなく、既存の堅牢なモデルを利用することができ、導入スケジュールを大幅に短縮することができます。LLMの拡大は、基礎となるモデルの精度と関連性を向上させるLLMの微調整に対する需要の高まりによって、さらに推進されています。ドメイン固有のデータセットの増加や、人間のフィードバックからの強化学習(RLHF)などの微調整技術の進化も、市場の成長を刺激しています。
アジア太平洋地域のAIトレーニングデータセット市場は、企業による多額の投資と積極的な取り組みの結果、大幅に拡大する見込みです。例えば、中国の自律走行部門では、自動運転アルゴリズムの訓練と改良のために、1,000万kmを超える実走行データを記録したBaiduのApolloのような膨大なデータセットを活用しています。さらに、インドのアグリテック分野では、AIを活用して農業の課題に取り組んでいます。インド政府が支援するイニシアチブAgriStackは、土壌の状態から作物の成長パターンまで広範なデータセットをコンパイルすることでデジタル・エコシステムを構築し、農家向けのAIソリューションを強化することを目指しています。
シンガポールのスマート・ネイション・プロジェクトも、オープン・データ・アーキテクチャを採用することでデータの共有性を高めることを目的とした政府政策の一例です。民間企業が公共データセットを活用することで、都市管理、交通、ヘルスケアに最適化されたAIモデルを迅速に開発することができます。また、日本の理化学研究所と自動車大手のトヨタ自動車が提携し、高度なロボット工学と人間と機械の相互作用に焦点を当てたデータセットを作成した例もあります。アジア太平洋地域は、専門的で地域に関連したデータセットと戦略的な官民連携を重視しており、AIトレーニングデータセット市場の急成長を牽引しています。
2024年9月、InnodataはAI/MLモデルのトレーニングを効率化するために設計されたオンデマンドデータセットを提供する革新的なプラットフォーム、AI Data Marketplaceを立ち上げました。キュレーションされた合成文書データセットに重点を置き、今後も拡張を予定しているこのマーケットプレイスは、データサイエンスチームがデータ量、多様性、プライバシーに関連する課題に取り組めるよう支援します。
2024年9月、AWSはAWS SageMaker Data Wranglerを強化し、Data Quality and Insightsレポートの作成、Salesforce Data Cloudからのデータインポート、推論エンドポイントへのデータフローのエクスポート機能など、いくつかの新機能を追加しました。さらに、SaaSプラットフォームやDatabricksからのデータのインポート、時系列データの変換、主成分分析(PCA)を変換メソッドとして使用することも可能になりました。
2024年3月、Appenは大規模言語モデル(LLM)の効率的なカスタマイズを支援する新しいプラットフォーム機能を発表しました。主な機能強化には、モデル選択、データ準備、プロンプト作成、モデル最適化、安全性保証のための合理化されたプロセスが含まれ、企業は独自のデータとAppenのクラウドキュレーションデータの両方を活用して、AIアプリケーション開発を改善することができます。
2024年2月、GoogleとRedditは提携し、GoogleはRedditのデータAPIにアクセスすることで、より効率的なAIモデルトレーニングを実現し、RedditはGoogleのVertex AIにアクセスすることで、検索機能を強化します。この提携は、Redditのデータ収益化とビジネス提供の向上を支援するものです。
2024年1月、エヌビディアは、開発者がさまざまな業界にわたる大規模言語モデル(LLM)をトレーニングするための合成データを生成できるオープンなモデルファミリーであるNemotron-4 340Bをリリースしました。このモデルは、エンドツーエンドのモデルトレーニングのためのオープンソースフレームワークであるNVIDIA NeMoと、スケールでの効率的な推論のためのNVIDIA TensorRT-LLMとの使用に最適化されています。
2023年11月、AppenはAmazon Web Services(AWS)と提携し、AWSのクラウド機能をAIデータのソーシング、アノテーション、モデル評価に活用することで、AIイノベーションを強化します。この複数年にわたるパートナーシップは、ドメインエキスパートの資格認定を大規模に効率化することを目的とした新しい評価AIツールを含む、高品質のトレーニングデータソリューションの開発に注力します。
主要企業・市場シェア
AIトレーニングデータセット市場は、幅広い地域で事業を展開する少数の大手企業によって支配されています。AIトレーニングデータセット市場の主要プレーヤーは以下の通り。
Scale AI (US)
Appen (Australia)
Lionbridge (US)
AWS (US)
Sama (US)
Cogito Tech (US)
Cloud Factory (UK)
TELUS International (Canada)
Innodata (US)
iMerit (US)
TransPerfect (US)
Clickworker (UK)
Google (US)
LXT (Canada)
IBM (US)
Microsoft (US)
NVIDIA (US)
【目次】
5.1 はじめに
5. 2 市場ダイナミクスの動因 – AI生成モデルのための多様で継続的に更新されるマルチモーダルデータセットへのニーズの高まり – 会話型AIにおける多言語データセットの利用の増加 – 自律走行車のための高品質なラベル付けデータへの需要の高まり – レアイベントシミュレーションのための合成データの採用の増加 – 制限事項 – 著作権侵害によるウェブスクレイピングデータの法的リスク – HIPAAコンプライアンスによる高品質な医療データセットへのアクセスの制限 様々な分野での専門的なデータアノテーションサービスに対する需要の高まり 合成データの生成と拡張トレーニングデータ用のプライバシー保護技術 企業ソリューション用にカスタマイズされたAIデータセットと専用フォーマットの作成 チャレンジ – データの品質と関連性の問題 – 多様なデータセットフォーマットと一貫性のないアノテーション手法
5.3 AIトレーニングデータセットの進化
5.4 サプライチェーン分析
5.5 エコシステム分析 データ収集ソフトウェアプロバイダー データラベリングとアノテーションプラットフォームプロバイダー 合成データプロバイダー データ増強ツールプロバイダー 既製(ots)データセットプロバイダー AIトレーニングデータセットサービスプロバイダー
5.6 投資と資金調達のシナリオ
5.7 生成型AIがAIトレーニングデータセット市場に与える影響 画像認識のためのデータ補強 NLPのための合成テキスト生成 音声・音声データ合成 シミュレートされたユーザーとの対話 データセットにおけるデータの偏り緩和 予測モデルのためのシナリオテスト
5.8 ケーススタディ分析 ケーススタディ1:クリックワーカー、自動車システムのAIトレーニングデータセットを強化し、音声認識精度を向上 ケーススタディ2: ケーススタディ3:Cogito Tech LLC、Ai駆動型大動脈弁データセットで心臓外科手術を強化 ケーススタディ4:Superannotateを使用したヒンジヘルスの成功により、疼痛軽減のためのAiトレーニングデータセットを強化 ケーススタディ5:Outreach、Label StudioでAiトレーニングを強化 ケーススタディ6:encord、データ品質と効率性を向上させる手術ビデオアノテーションの主要課題に対処
5.9 技術分析 主要技術 – データのラベリングとアノテーション – 合成データの生成 – データの増強 – HITL(Human-in-the-Loop) フィードバックシステム – 能動学習 – データのクレンジングと前処理 – バイアスの検出と緩和 – データセットのバージョン管理と管理 補助技術 – クラウドストレージとデータレイク – MLOpsとモデル管理 – データガバナンス – 機械学習フレームワーク 補助技術 – 連携学習 – データ処理のためのエッジAI – 差分プライバシー – AutoML – 転送学習
5.10 規制の状況 規制機関、政府機関、その他の組織の規制 AI TRAINING DATASET- 北米- 欧州- アジア太平洋- 中東&アフリカ- 中南米
5.11 特許分析方法論 出願された特許, 文書タイプ別 イノベーションと特許出願
5.12 価格分析 価格設定データ:製品タイプ別
5.13 主要会議とイベント、2024-2025年
5.14 ポーターの5つの力分析 新規参入の脅威 代替品の脅威 供給者の交渉力 買い手の交渉力 競争相手の強さ
5.15 主要ステークホルダーと購買基準 購買プロセスにおける主要ステークホルダー 購買基準
5.16 顧客のビジネスに影響を与えるトレンド/混乱
AIトレーニングデータセット市場:提供製品別
132
6.1 オファリングの導入 AIトレーニング用データセット市場の促進要因
6.2 データセットの作成 堅牢なAiアプリケーション開発の鍵となるデータセットの作成
6.3 データセット販売:倫理的データ販売によるAi開発用データの収益化
AIトレーニング用データセット市場(データセット作成別
7.1 はじめに データセット作成:AIトレーニング用データセット市場の促進要因
7.2 データセット作成ソフトウェア データセット作成ソフトウェアは様々な分野でのイノベーションを促進 データ収集ソフトウェア – ウェブスクレイピングツール – データソーシングAPI – クラウドソーシングプラットフォーム – センサーデータ収集ソフトウェア データラベル付けとアノテーション – 画像アノテーション – テキストアノテーション – 動画アノテーション – 音声アノテーション – 3Dデータアノテーション シンセティックデータ生成ソフトウェア データ補完ソフトウェア
7.3 データセット作成サービス 最適なAIモデルアライメントのためのカスタマイズされたデータ作成サービス データ収集サービス データアノテーション&ラベリングサービス データ検証サービス
AIトレーニングデータセット市場、データセット販売別
8.1 データセット販売の導入:AIトレーニングデータセット市場の促進要因
8.2 既製(OTS)データセットのスケーラビリティと配布の容易さが、OTSデータセットをAIトレーニングに魅力的なものに
8.3 データセット・マーケットプレイス データセット・マーケットプレイスは、重要なリソースへのアクセスを民主化することで、AIのイノベーションを加速
AIトレーニング用データセット市場、アノテーションタイプ別
9.1 導入 アノテーションタイプ: AIトレーニングデータセット市場の促進要因
9.2 高品質なラベル付け済みデータセットが様々な分野のAI開発を加速
9.3 非ラベル化データセット 非ラベル化データセットによりロバストなAIモデル学習が可能に
9.4 合成データセット 生成モデルの進歩により合成データセットの品質が向上 AIトレーニングデータセット市場、データモダリティ別
AIトレーニングデータセット市場、データモダリティ別
10.1 導入データの種類 AIトレーニング用データセット市場の促進要因
10.2 テキストビジネスでは、モデルの精度を高めるために、多様なラベル付きテキストデータセットのキュレーションを優先 テキスト分類 チャットボット センチメント分析 ドキュメント解析 その他のテキストデータモダリティ
10.3 画像 ディープラーニング技術、特に畳み込みニューラルネットワークの進歩により、AI 開発における画像データの役割が高まる 物体検出 顔認識 医療画像 衛星画像 その他の画像データモダリティ
10.4 音声・スピーチ 音声認識、音声分類、音楽生成、音声合成、その他の音声・スピーチデータモダリティ。
10.5 動画コンテンツの可能性を活用しようとする企業による高品質なラベル付き動画データセットの需要急増 アクション認識 自律走行 動画監視 動画コンテンツ調整 その他の動画データモダリティ
10.6 マルチモーダル データセットに対する需要の高まりがAIアプリケーションの革新と進歩を後押し 音声対テキスト コンテンツ推薦 ビジュアル質問応答(VQA) マルチモーダル分析 その他マルチモーダル
AIトレーニングデータセット市場、タイプ別
11.1 導入タイプ: AIトレーニングデータセット市場の促進要因
11.2 ジェネレーティブAI ジェネレーティブAIは、多様なトレーニングデータセットを通じて、業界全体の創造性に革命を起こすllm 評価ラグ最適化llm ファインチューニング会話エージェントコンテンツ作成コード生成その他のジェネレーティブAI
11. 3 エンタープライズAIアプリケーションにおけるNLPとコンピュータ・ビジョンの役割の高まりによる他のAIデータセット需要の増加 自然言語処理(NLP)- テキスト分類- 有名表現認識(NER)- センチメント分析- 文書の解析と抽出 コンピュータ・ビジョン- 画像分類- 物体検出- ビデオ分析- 光学式文字認識(OCR) 予測分析- 時系列予測- 異常時予測- 時系列予測- 時系列予測- 異常時予測- 時系列予測 時系列予測 – 異常検知 – 顧客行動予測 – リスクスコアリングと管理 レコメンデーションシステム – 製品およびコンテンツのレコメンデーション – パーソナライズされたマーケティングと広告 – 協調フィルタリング 音声および音声処理 – 音声認識 – 音声分類 – 音声コマンド認識 – 音声からテキストへの文字起こし その他の種類
AIトレーニングデータセット市場、エンドユーザー別
12.1 導入エンドユーザー:AIトレーニングデータセット市場の促進要因
12.2 bfsi 金融機関がAIトレーニングデータセットを活用して不正検知とリスク管理を強化 銀行 金融サービス 保険
12.3 通信事業者 通信事業者はAIを活用したインテリジェントシステムで業績と顧客サービスを向上
12.4 政府・防衛 AIのトレーニングデータセットが国家安全保障と防衛活動の進展を促進
12.5 ヘルスケア&ライフサイエンス AIトレーニングデータセットが精密医療と診断の画期的な進歩を先導
12.6 製造業 AIトレーニングデータセットが自動化と予知保全で製造業の効率化を促進
12.7 小売・消費財 小売企業は、AIを活用したレコメンデーションと最適化されたサプライチェーンにより、パーソナライズされた顧客体験を強化。
12.8 ソフトウェア&テクノロジー・プロバイダ クラウド・ハイパースケーラ 基盤モデル/LLMプロバイダ AIテクノロジー・プロバイダ IT&IT対応サービス・プロバイダ
12.9 自動車 実際の運転行動や状況を捉えたAiトレーニング・データセットが後押しする自律走行車開発の急速な進歩
12.10 メディア&エンターテイメント AIトレーニングデータセットがメディア、ゲーム、エンターテイメント業界のコンテンツ制作におけるイノベーションを促進
12.11 その他のエンドユーザー
…
【本レポートのお問い合わせ先】
https://www.marketreport.jp/contact
レポートコード:TC 9212
- 世界の地熱掘削ビット市場・予測 2025-2034
- セテアレス-80市場:グローバル予測2025年-2031年
- ソーラーパネルテスター市場2025年(世界主要地域と日本市場規模を掲載):直流電圧1000Vまで、直流電圧1500Vまで、その他
- 電解研磨装置の世界市場2025:種類別(自動、手動)、用途別分析
- 健康食品の中国市場:ビタミン・ミネラル、体重管理・スポーツ栄養サプリメント、ハーブ植物エキス、プロバイオティクス、その他
- オーディエンス分析の世界市場規模調査:ソリューション別、サービス別(プロフェッショナル、マネージド)、用途別(販売・マーケティング管理、顧客経験管理、競合情報)、組織規模別、業種別、地域別予測:2022年~2032年
- 世界の使い捨て型パルプ製尿瓶市場
- ハイドレーションベルト市場レポート:製品タイプ別(ボトル付き、ボトルなし)、流通チャネル別(スーパーマーケット、ハイパーマーケット、スポーツ専門店、直営店、オンライン、その他)、エンドユーザー別(スポーツ、軍事、その他)、地域別 2024-2032
- 都市計画ソフトウェアとサービスの世界市場規模調査、コンポーネント別(ソフトウェア、サービス)、展開別(クラウドベース、ウェブベース)、エンドユース別(政府、不動産、インフラ企業)、地域別予測:2022-2032年
- アクチュアリーサービス市場2025年(世界主要地域と日本市場規模を掲載):損失準備金認証、損失資金調達と支払予測、保険料率設定、キャプティブ保険会社設立可能性調査、自己負担額最適化、リスク移転意見、その他
- サーマルクリップオンシステム市場2025年(世界主要地域と日本市場規模を掲載):384×288、640×480、400×300、その他
- 膜バイオリアクターの世界市場規模は2030年までにCAGR 8.5%で拡大する見通し